- Apr 25, 2015
- 1,846
- 2
- 2,203
- 327
Video:
Download the PoC files: https://github.com/R4P3-Linux/TeamKilled
Crash character:
Vulnerability identifier courtesy of MITRE: CVE-2019-15502 [View the MITRE entry]
Also, a way to fuzz this would be to generate a list of ALL characters in for example Perl/Python going down the list of ALL unicode characters and just generate a big ass file filled with these characters. Or even generate a channel list by modifying the SQLite database - then launching the server.
Hold down the arrow key until your client crashes, as it tries loading in possible crash characters. Generate up, generate down, and even mix random chars in?
Here are some example unicode fuzzing lists:

 github.com
github.com
 github.com
https://www.lookout.net/2011/06/special-unicode-characters-for-error.html "Word Joiner U+2060 is an invisible zero-width character."
github.com
https://www.lookout.net/2011/06/special-unicode-characters-for-error.html "Word Joiner U+2060 is an invisible zero-width character."
 github.com
https://news.ycombinator.com/item?id=10035723 "People should also test what happens with isolated surrogate codepoints, such as U+D800. But these can't properly be encoded in UTF-8, so I guess don't put them in the BLNS. (If you put the fake UTF-8 for them in a file, the best thing for a program to do would be to give up on reading the file.)"
github.com
https://news.ycombinator.com/item?id=10035723 "People should also test what happens with isolated surrogate codepoints, such as U+D800. But these can't properly be encoded in UTF-8, so I guess don't put them in the BLNS. (If you put the fake UTF-8 for them in a file, the best thing for a program to do would be to give up on reading the file.)"
https://news.ycombinator.com/item?id=10035008 also shares "we had the EICAR string for testing but couldn't check it into source control because it triggered the AV"
https://github.com/fuzzdb-project/fuzzdb

 security.stackexchange.com
https://stackoverflow.com/questions...-characters-utf8-encoding-string-manipulation (using Ruby to get the job done)
security.stackexchange.com
https://stackoverflow.com/questions...-characters-utf8-encoding-string-manipulation (using Ruby to get the job done)
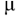 manishearth.github.io
https://i.blackhat.com/asia-19/Fri-...cient-Approach-to-Fuzzing-Interpreters-wp.pdf "We have found several bugs in those components, for example ones that occurred during parsing unicode encoded characters in the program source code."
manishearth.github.io
https://i.blackhat.com/asia-19/Fri-...cient-Approach-to-Fuzzing-Interpreters-wp.pdf "We have found several bugs in those components, for example ones that occurred during parsing unicode encoded characters in the program source code."
 http://index-of.co.uk/Hacking-Coleccion/Open Source Fuzzing Tools.pdf (the free PDF of the above, much nicer) also other PDFs listed http://index-of.co.uk/Hacking-Coleccion/
http://index-of.co.uk/Hacking-Coleccion/Open Source Fuzzing Tools.pdf (the free PDF of the above, much nicer) also other PDFs listed http://index-of.co.uk/Hacking-Coleccion/
That gets anyone started, for sure... but a few more anyway:

 stackoverflow.com
stackoverflow.com

 www.vertex42.com
www.vertex42.com
 vim.fandom.com
https://css-tricks.com/ordered-lists-unicode-symbols/ (dice for lists, hmm)
vim.fandom.com
https://css-tricks.com/ordered-lists-unicode-symbols/ (dice for lists, hmm)
Long story short, yeah you could generate a database filled with a bunch of characters. From there, launch the database and see what happens as you load the characters into TeamSpeak.
One could possibly find another Qt crash character. You never know!
Download the PoC files: https://github.com/R4P3-Linux/TeamKilled
Crash character:
Vulnerability identifier courtesy of MITRE: CVE-2019-15502 [View the MITRE entry]
Code:
> [Suggested description]
> The
> TeamSpeak
> client 3.3.0 allows remote servers to trigger a crash via the 0xe2 0x81 0xa8 0xe2 0x81 0xa7
> byte sequence, aka Unicode characters U+2068 (FIRST STRONG ISOLATE)
> and U+2067 (RIGHT-TO-LEFT ISOLATE).Also, a way to fuzz this would be to generate a list of ALL characters in for example Perl/Python going down the list of ALL unicode characters and just generate a big ass file filled with these characters. Or even generate a channel list by modifying the SQLite database - then launching the server.
Hold down the arrow key until your client crashes, as it tries loading in possible crash characters. Generate up, generate down, and even mix random chars in?
Here are some example unicode fuzzing lists:
SecLists/Fuzzing/big-list-of-naughty-strings.txt at master · danielmiessler/SecLists
SecLists is the security tester's companion. It's a collection of multiple types of lists used during security assessments, collected in one place. List types include usernames, passwords, ...
github.com
GitHub - cweb/unicode-hax: A library to assist in security-testing Unicode enabled applications during fuzzing, XSS, SQLi, etc.
A library to assist in security-testing Unicode enabled applications during fuzzing, XSS, SQLi, etc. - cweb/unicode-hax
github.com
GitHub - minimaxir/big-list-of-naughty-strings: The Big List of Naughty Strings is a list of strings which have a high probability of causing issues when used as user-input data.
The Big List of Naughty Strings is a list of strings which have a high probability of causing issues when used as user-input data. - minimaxir/big-list-of-naughty-strings
github.com
https://news.ycombinator.com/item?id=10035008 also shares "we had the EICAR string for testing but couldn't check it into source control because it triggered the AV"
https://github.com/fuzzdb-project/fuzzdb
Does it have sense to fuzz a ASCII file format with mutators that mess with Unicode or String Case?
I'm trying to fuzz an ASCII file format. Specifically, I'm defining some HTML5/HTML structures to be used as definition file for a smart fuzzer to fuzz web browsers. This smart fuzzer allows to exc...
security.stackexchange.com
Mitigating underhandedness: Fuzzing your code
This may be part of a collaborative blog post series about underhanded Rust code. Or it may not. I invite you to write your own posts about underhanded code to make it so! The submission deadline for …
manishearth.github.io
Open Source Fuzzing Tools
Fuzzing is often described as a "black box software testing technique. It works by automatically feeding a program multiple input iterations in an attempt to trigger an internal error indicative of a bug, and potentially crash it. Such program errors and crashes are indicative of the existence...
books.google.com
That gets anyone started, for sure... but a few more anyway:
Generate a list of unicode characters in a for loop
I am trying to list use the counter in a for loop as the number of a Unicode character. To use a Unicode character in JavaScript one can either type it in as it is, or use an escape sequence like: ...
stackoverflow.com
Huge List of Unicode Character Symbols
This page provides a set of tables for Unicode character symbols, including emojis, emoticons, arrows, music, sports, etc.
www.vertex42.com
Generate all Unicode characters
You can generate a table of Unicode characters in Vim to see how they are displayed by your system. This may be of interest to anyone using CJK characters. Example The following will add a table showing the characters from hex 9900 to 9fff, inclusive: :call GenerateUnicode(0x9900, 0x9fff)...
Long story short, yeah you could generate a database filled with a bunch of characters. From there, launch the database and see what happens as you load the characters into TeamSpeak.
One could possibly find another Qt crash character. You never know!
Last edited: